The Road to Load Balancing
Clement
25 min read·Sep 17, 2022
Load Balancing 是实现高可用性的重要手段,它可以在系统的各个环节中发挥作用——当我们打开网页或者启动一个app时,它就开始发挥作用了。
我没法把 Load Balancing 讲得很透彻,但我的理解或许可以提供一个新的视角。
后端程序通常给客户端提供服务,那么客户端与后端服务打交道的第一站—网关—有必要做到高可用。
最简单的网关可能长这样:
在这个场景中,Nginx成了单点故障。为了让Nginx高可用,很容易想到这个方案:
在这个场景中,我们希望当一台Nginx服务器宕机后,客户端会遍历DNS A记录列表,找到存活的IP地址,将后续的请求发送到存活的Nginx。
在理想情况下,现代浏览器会尝试挨个连接IP,直到找到可用的IP地址。
在糟糕的情况下,过时的浏览器并不会进行这样的IP切换。或许它们直接使用了操作系统的DNS策略。
依靠DNS实现故障切换的缺陷包括:
要解决这个问题,可能的方案/线索有:
有没有低成本且自动化的方案来实现一个高可用的网关呢?
可以考虑keepalived + LVS/HAProxy/Nginx方案 。
多台LVS/HAProxy/Nginx机器组成一个虚拟路由器,这个虚拟路由器对外的IP地址是固定的。 所有来自客户端请求都发送到虚拟路由器中的master机器;当master宕机时,keepalived从多个slave中选举出新的master。 如此一来,开发者无需修改DNS记录和客户端代码,就拥有了高可用的网关。 这个方案相对复杂,运维成本较高,当来自客户端的请求异常多的时候,它的可用性有待验证。
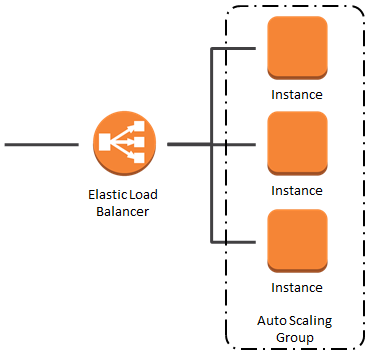
云服务商几乎都提供了开箱即用的Load Balancer(比如AWS的ELB、阿里云的SLB)。
运维资源有限的团队不妨直接使用云服务商提供的Load Balancer。它们通常基于专有的软、硬件开发,并且它们的稳定性和可用性较高;但也没有宣传的那么高,时不时也会崩溃。
来自客户端的请求经过网关,进入后端服务后,常常会触发后端服务之间的相互调用(RPC):
为了防止Service B单点故障,Service B拥有3个运行中的实例。Service A每次发起RPC调用时,只需要调用Service B的一个实例。
Service A如何知道这次的PRC应该调用那个Service B实例呢?
配置文件的缺点:
考虑使用hashicorp/consul, etcd.io/etcd 等工具提供的服务发现功能。
直到这里,还有个问题没有解决:通过上述方式,Service A 知道了 Service B 的3个实例的IP地址,但是本次RPC到底该调用instance01还是instance02呢? 那就使用Load Balancing算法吧。
常见的Load Balancing算法:
这些算法可以在 Service A 的代码中实现,但是这会大大增加项目的复杂度。使用一个微服务框架即可拥有开箱即用的Load Balancing算法。 微服务框架不仅提供Load Balancing算法,还包含了服务发现、限流、断路器等常用功能。 参考cloudwego/kitex,go-micro/go-micro 等微服务框架。
如果 Service B 是一个用上古语言 COBOL 开发的服务,无法使用服务发现功能呢?那就使用Kubernetes吧。
在Kubernetes中,Service A 和 Service B 的每个实例以容器方式运行,每个容器也叫做Pod。每个实例都有自己的独立IP地址,它们可以通过IP地址互相访问。
它们也可以通过域名(服务名)互相访问,例如 Service A 能使用域名 service-b 访问到Service B的实例,并且在访问过程中Kubernetes默认会运用Round-robinLoad Balancing算法。
可以看到Kubernetes替我们处理了服务发现和Load Balancing,但这是怎么发生的呢?
在一个由很多台机器组成的Kubernetes集群中,Service A 和 Service B 的Pod分布在3台机器上。Kubernetes将Pod抽象为endpoint, 每个endpoint都具有唯一的IP地址:
Kubernetes的核心组件——API Server——记录着service与endpoint之间的映射关系。
Kubernetes集群中的每台机器上都运行着一个kube-proxy进程,它与API Server交换信息,并将service与endpoint之间的映射关系写入本机Linux系统的iptables)中,供本机上运行的所有Pod使用:
iptables如何发挥作用呢?
当Pod使用service-b作为域名发出网络请求时,内核会接管这个网络请求,根据round-robin算法从iptables中选择一个目标IP地址作为目的地。如下:
上面的描述其实有问题:域名service-b是如何跟随网络请求进入内核的?我们知道TCP/IP协议的IP包头中是没有域名的,只有IP地址。所以Pod必须在User
Space内将域名service-b转换成IP地址。在Kubernetes中,这个IP地址叫做"Service ClusterIP"。Linux的iptables可以记录Service
ClusterIP到Endpoint IP的映射关系,使用iptables -t nat -L命令查询一组具体的规则:
$ iptables -t nat -L KUBE-SVC-VU34GOJGBTT6YNCZ
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.99.103.173 /* app/service-b:service-b cluster IP */ tcp dpt:http-alt
KUBE-SEP-GDJRRRLMGGNV4UYQ all -- anywhere anywhere /* app/service-b:service-b -> 10.244.0.136:8080 */ statistic mode random probability 0.50000000000
KUBE-SEP-Q6RFLNPN4L5SAQQU all -- anywhere anywhere /* app/service-b:service-b -> 10.244.0.137:8080 */
KUBE-SEP-Q6RFLNPN4L5SAQQU all -- anywhere anywhere /* app/service-b:service-b -> 10.244.0.138:8080 */
可以看到Service ClusterIP经过2次转换,就能找到目标Pod的IP地址:
10.99.103.173 ==> app/service-b:service-b ==> 10.244.0.136:8080,10.244.0.137:8080,10.244.0.137:8080
下图更详细地流程展示Pod如何发出网络请求:
CoreDNS是Kubernetes的组件之一,它记录着集群内部的域名和IP地址的映射,为Pod提供域名解析服务。
iptables本身没有Load Balancing算法,借助statistic extension 可以实现round-robin和random。 同时iptables的查找方式是线性的,当Service和Pod数量太多时,会遇到性能瓶颈。
kube-proxy可以使用IPVS模式 替代iptables模式。IPVS模式提供了O(1)效率的查找算法和更多的Load Balancing算法:
以上的内容能帮助我们理解Kubernetes集群中Load Balancing的机制,但是实际的Load Balancing场景要更复杂。下文将讨论在实际工作中可能遇到的问题。
在Kubernetes中使用gRPC会遇到一个经典问题: 使用基于HTTP2.0的gRPC进行服务间RPC时,可能出现严重的流量倾斜。Service A 发往 Service B 的请求全部被路由到了 Service B 的一个Pod,剩余的Pod没有收到任何请求:
HTTP/2 被设计为具有单个长期 TCP 连接,所有请求都是多路复用的,这意味着多个请求可以在任何时间点在同一个连接上处于活动状态 。 当一个TCP连接建立后,gRPC就不再创建新的连接。基于HTTP1.1的gRPC的一个连接只能处理一个请求,当出现并发请求时gRPC被迫创建新的连接,这使得流量被Load Balanced了。所以只有基于HTTP2.0的gRPC会遭遇流量倾斜的问题。
有3个常用的方法能够解决这个问题。
方案① Headless Service
如果将Service B定义成一个Headless Service:
apiVersion: v1
kind: Service
metadata:
name: service-b
spec:
clusterIP: None # <= Don't forget!!
selector:
app: web
ports:
- protocol: TCP
port: 8080
targetPort: 8080
Service A 的Pod便可以通过DNS请求查询到Service B的Pod的IP列表。gRPC库使用service-b作为域名发起DNS查询请求,从CoreDNS得到域名service-b的Pod的IP列表:
// don't use "service-b:8080", or grpc takes only one IP address from the DNS result and ignore the rest
dial, err := grpc.Dial("dns:///service-b:8080",
grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy":"round_robin"}`),
)
if err != nil {
log.Fatal(err)
}
client = api.NewUserGraphServiceClient(dial)
gRPC库默认从DNS解析结果的多个IP地址中选取第一个IP(pick_first)建立一个连接。示例代码使用了round_robin
策略,使得gRPC与IP列表里的每个IP建立一个连接,这些连接组成一个连接池,接下来gRPC库会将RPC请求依次发送给连接池中的一个连接。
为了应对后续的DNS记录变化,用户仍然需要自己编写代码定时查询DNS记录,当IP列表变化时,通知gRPC使用最新的IP列表:
Cons:
方案② Service Mesh
Service Mesh是个庞大的话题,不做深入讨论。解决方案参考
Cons:
仅仅为了实现Load Balancing而引入Service Mesh未必是好主意;如果Service Mesh的多个特性(比如健康检查、request-level metrics、mutual TLS等)都能为团队和业务带来收益时,不妨引入Service Mesh。
方案③ 微服务框架
主流的微服务框架包含了服务发现、Load Balancing、限流、断路器等常用功能。一旦用上了微服务框架的服务发现,Service A 就不必通过Kubernetes 的DNS解析来发现Service B的Pod的IP列表了;Service A可以直接从注册中心拿到Service B的Pod的IP列表。并且当IP列表发生变化时,注册中心会及时向Service A推送最新的IP列表。微服务框架的在感知到IP列表更新时,会更新连接池。
微服务框架的Load Balancing模块会根据用户指定的策略,孜孜不倦地从这个连接池中选择一个连接,作为RPC请求的目标。
Cons:
不论是round-robin还是least connection,它们选择candidate时候,都没有考虑到各个candidate实际的压力和健康状况( 根据connection数量不足以推测出candidate的压力)。
这或许是有价值的:编写一种Load Balancing算法,它观察历史网络请求的延迟、成功率,根据观察结果选出一个最佳的candidate。
这类算法已经诞生,并且被用于一些开源组件。Peak EWMA 是其中之一,它被应用在Linkerd、Twitter的Finagle以及ingress-nginx等软件中。
自2018年起,ingress-nginx就有了Peak EWMA算法:
Power of Two Choices 算法的思路令人耳目一新。
failed to fetch permalinkfailed to fetch permalink